WEEK 36 + 37
Project: Shiny App
Started on: Feb 26, 2023
Ended on: Mar 4, 2023
Staff Guidance: Stacy
Description:
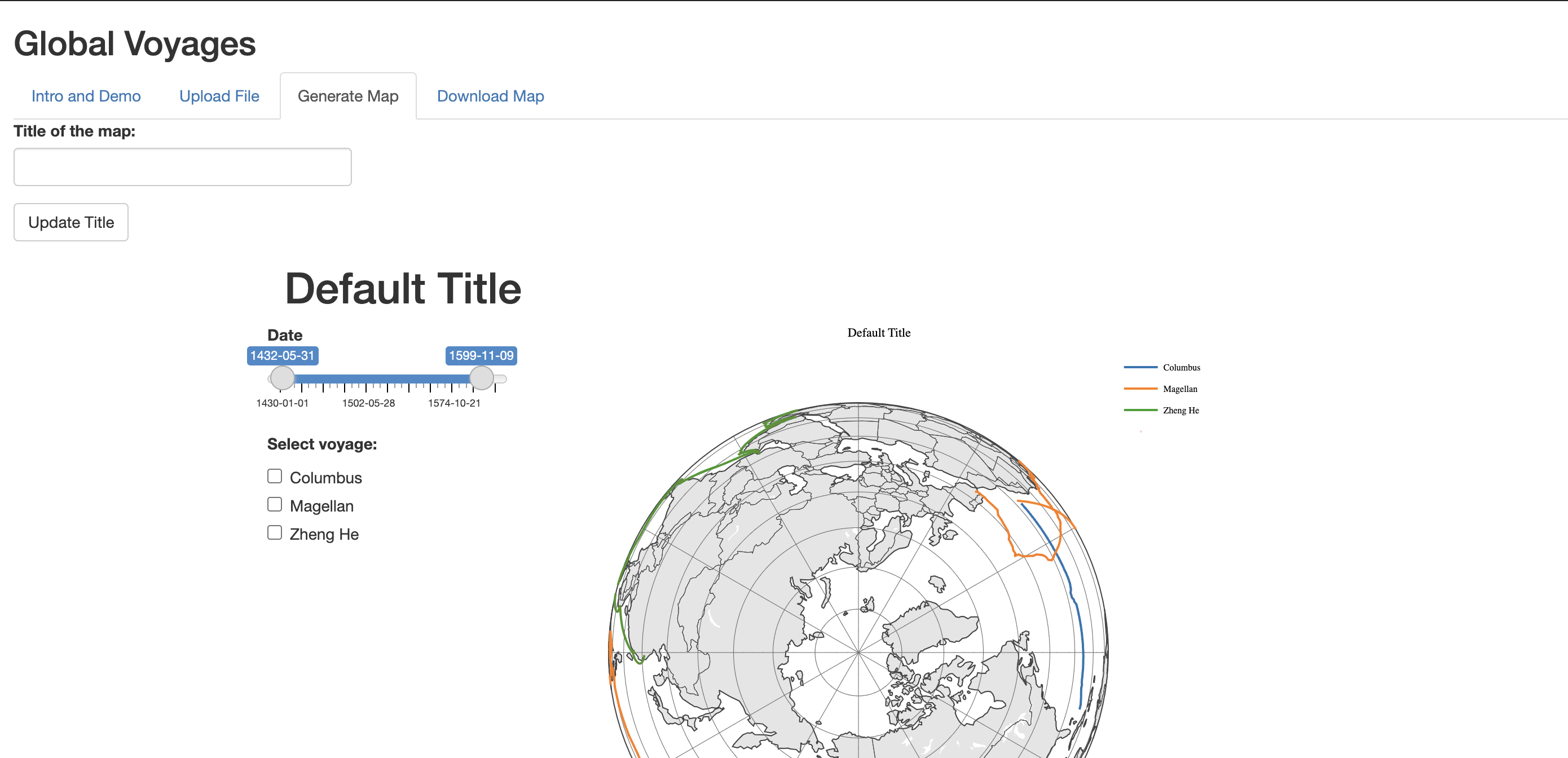
- Simply put: the slider works perfectly after I put the whole map with slider into a temporary HTML file.
- The server is created and hosted with deployment and production site. https://cliomaps.development.la.utexas.edu/
- If the server does not work, use this instead: https://clioviz.shinyapps.io/Cliomaps_2024_02_27/.
- The server site only works if you are on campus. The client loves it.
- Use this CSV file for testing out the app: https://raw.githubusercontent.com/BrianTruong23/amazon_predicting_project/master/Voyages_2024_01_24.csv
Project: Shiny App (Part 2)
Started on: Mar 4, 2023
Ended on: Mar 7, 2023
Staff Guidance: Stacy
Description:
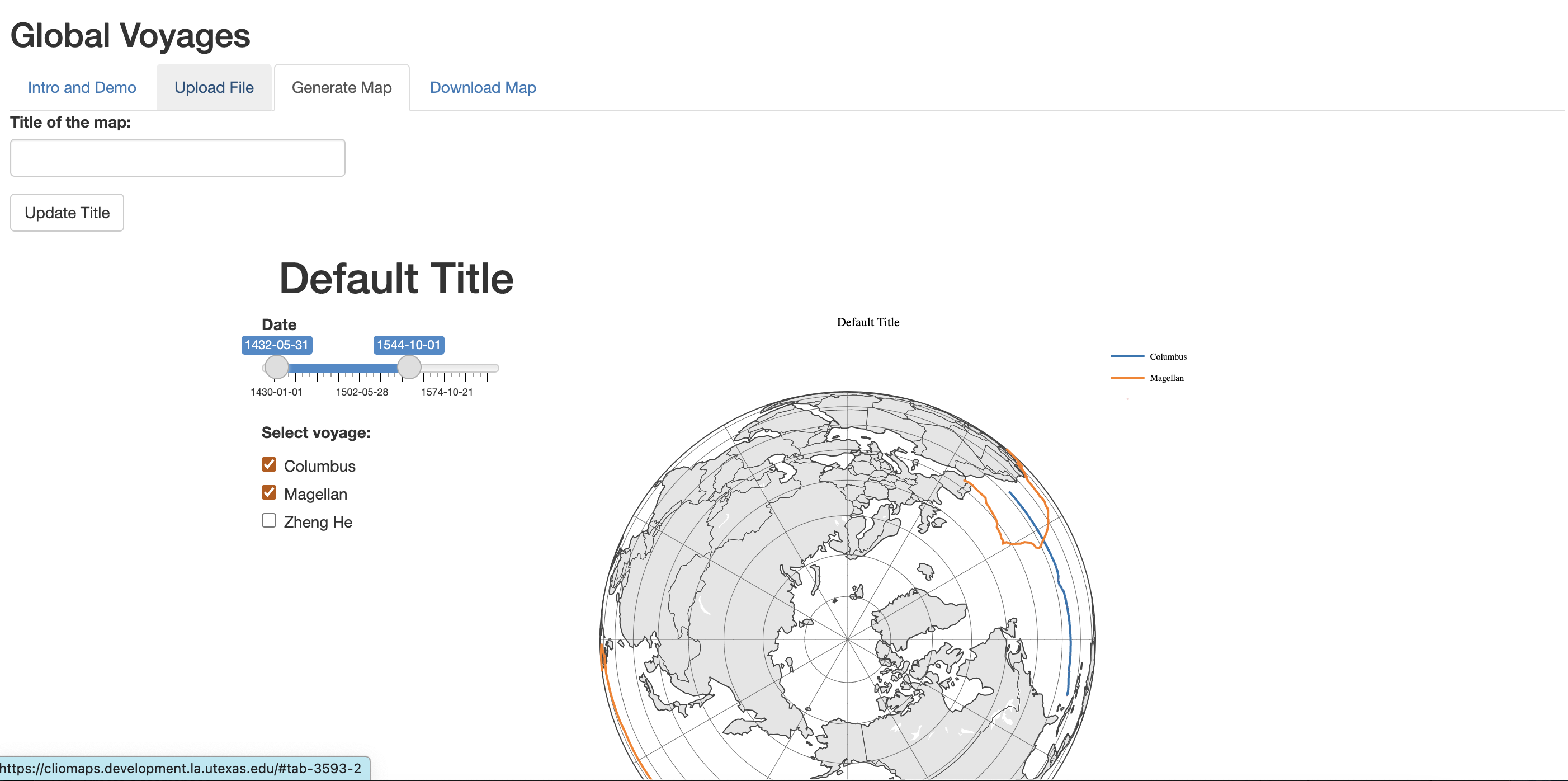
- The client wants a new map to be hosted and developed in shiny app.
- The process is very similar to the previous project when I need to display a fully functional map with sliders and zoom working properly.
- Therefore, applying what I know from before, I can generate a temporary HTML file and display that on the website
- Also, I just finished the functionality of downloading the map.
Project: Whisper AI
Started on: Feb 19, 2023
Ended on: Mar 4, 2023
Staff Guidance: Chris
Description: Finish the evaluation for Whisper AI
Whisper AI
- The Whisper AI converts the audio file into a spectrogram to analyze and predict the corresponding text captions.
- It takes a 30 second chunk of input, converts it into a log-Model spectrogram, analyzes the image and applies encoding-decoding architecture to predict the text caption based on those images.
Some key insights:
- Lower HST produces much cleaner version of text (not including filter words as much as higher HST (from 0.2 to 0.5))
- There are some variation of inference ability of each time: eg. truth work done instead of tooth work done. Therefore, a lot of words are predicted differently
- Even with the same threshold, there is variation in running the models from time to time.
- A lot of models do not capture the first intro sentence from the lady.
- 1.3 is the fastest and 0.1 is the slowest -> Might suggest that as the parameter increases, the time it takes is faster -> It means it does not need to re-process so many times. With 0.1, it means that it re-process every 0.1 sec after silence is detected -> suggesting more time to process